 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
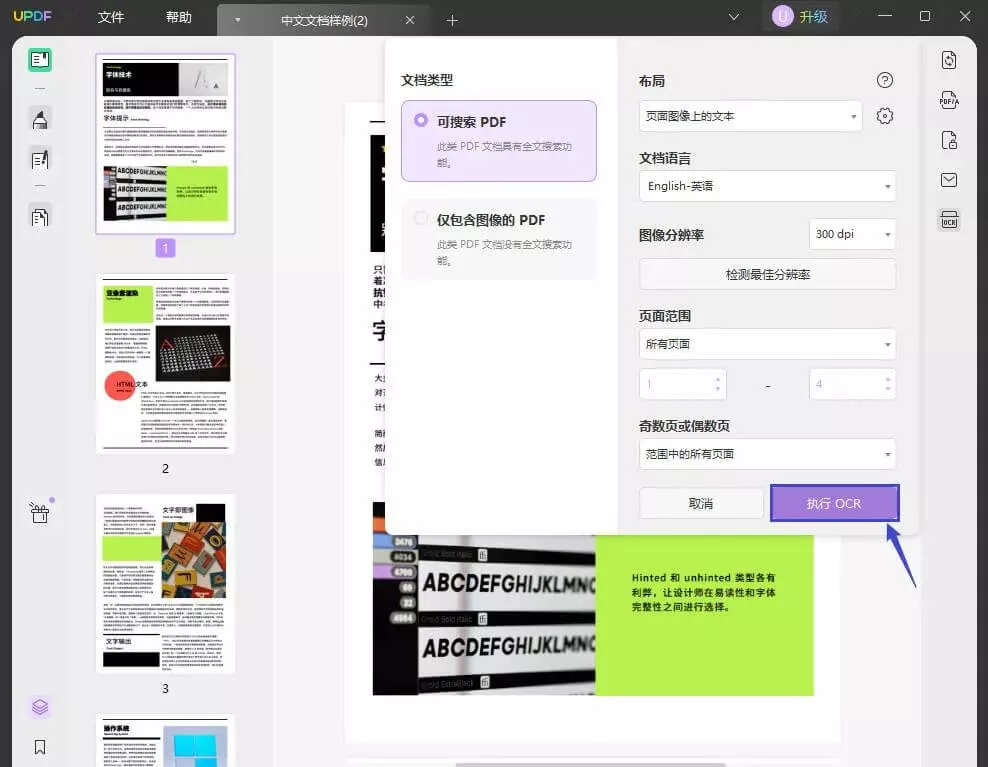
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志








在数字化信息不断增长的时代,OCR(光学字符识别)技术逐渐成为各行业不可或缺的工具。无论是扫码付款、电子文档管理,还是电子书的制作,OCR技术都给予了我们极大的便利。那么,OCR图文识别究竟是什么原理?它是如何工作的呢?本文将为你详细解读这一技术的运作机制。
一、OCR技术概述
OCR是一种能够将扫描的文档或图片中的文本转换为可编辑和可搜索的数字文本的技术。OCR不仅限于文字的识别,随着技术的进步,它还可以处理手写文字、图像以及复杂的排版格式等。其应用范围广泛,从纸质文档的数字化到邮件地址的自动识别,无不在影响着我们的生活和工作。

二、OCR的工作流程
OCR图文识别的工作流程大致可以分为以下几个步骤:
1. 图像获取:首先,OCR系统需要从扫描仪、手机相机或其他数字设备获取图像。这一步骤的质量直接影响OCR的识别准确性。
2. 图像预处理:获取的图像往往需要经过一系列的预处理,例如去噪声、二值化、倾斜校正等,以提升后续文字识别的效果。预处理的目的是为了提高图像的清晰度和对比度,使得文字部分更为突出。
3. 文字分割:在预处理完成后,OCR系统会对图片进行文字分割,即将图像中的文本区域与背景分隔开来。这个过程需要准确识别出字符、单词、行之间的边界。
4. 字符识别:文字分割完成后,系统会将每个字符进行识别。现代OCR技术通常采用机器学习和模式识别算法,通过特征提取将字符与数据库中的模型进行比对。这一阶段是OCR的核心步骤,直接影响识别的准确性。
5. 后处理:字符识别后,OCR系统会对识别结果进行后处理,包括拼写检查和格式调整。后处理的目的是对识别结果进行优化和补充,确保输出的文本无误。
6. 输出文本:最后,处理后的文本会被输出为电子文件,支持多种格式,如TXT、PDF、Word等,方便用户存储和使用。
三、OCR的技术原理
了解OCR的工作流程后,我们来深入探讨其核心技术原理:
1. 图像处理技术
首先,OCR图文识别离不开高效的图像处理技术,包括但不限于:
– 灰度处理:将彩色图像转换为灰度图像,减少颜色信息的处理复杂性。
– 二值化:将灰度图像转换为黑白图像,以便于后续的字符识别。这一过程通过设定阈值来判断像素的归属。
– 噪声去除:利用滤波算法去除图像中的噪声,确保文字部分的清晰度。
2. 机器学习与深度学习
OCR技术近年来逐渐向深度学习迈进,通过大量的训练数据来提升识别准确度:
– 卷积神经网络(CNN): CNN是一种常用于图像识别的深度学习结构,能够有效提取图像中的特征。
– 循环神经网络(RNN):在处理页面上的文本行时,RNN能更好地捕捉字符与字符之间的关系,从而提高识别的连贯性。
3. 模式识别
模式识别是OCR系统识别字符的关键技术,主要包括两种方式:
– 模板匹配:通过与预设的字符模板进行比对的方式进行识别,适合于字体较为简单的文本。
– 特征提取法:通过特征提取算法提取字符的独特特征,建立特征库进行识别,更适合复杂字体与手写体。
4. 语言模型
OCR不仅仅依靠图像和字符的识别,语言模型在其中也发挥着重要的作用。语言模型通过上下文、语法等信息对识别结果进行修正,提高整体的识别准确性。
四、OCR技术的应用领域
OCR技术在各行各业中的应用日益增多,以下是一些重要的应用领域:
– 文档数字化:许多企业通过OCR将纸质文件转换为电子文档,实现文档管理的高效化。
– 票据识别:在金融行业,OCR被广泛用于支票、发票的自动识别与处理,大大提高了工作效率。

– 车牌识别:在交通管理中,OCR技术能够迅速破解车牌号码,辅助交通监控与管理。
– 图书馆与档案馆:利用OCR技术对古籍和档案进行数字化保存,实现文献的保护与利用。
五、当前OCR技术的挑战与未来发展
尽管OCR技术已取得了显著进展,但仍面临一些挑战:
– 手写体识别:目前,对手写体的识别准确率仍然低于印刷体,提升手写体的识别率依旧是技术发展的难点。
– 语言与字体的多样性:不同语言、不同字体的多样性使得OCR系统需要更丰富的训练数据,以确保更好的适应性。
– 格式复杂度:对于格式复杂的文档,如多栏排列、嵌入图片的文本,OCR仍然需要进一步优化识别算法。
未来,OCR技术将继续朝着智能化、人性化的方向发展,结合人工智能、自然语言处理等新兴技术,提升识别的准确率与效率。
总结
OCR图文识别作为一种先进的技术,其背后的原理与工作机制复杂而精妙。通过不断的技术更新与算法优化,OCR技术正在为我们的日常生活带来全面的便利,从文档管理到智能识别,涵盖面广,前景广阔。随着科技的推进,OCR的应用将更加深入,极大提升工作效率与生活品质。
