 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志







在当今数字化的时代,PDF格式已经成为了信息交换的重要载体,尤其是在报表和表格数据的展示上。尽管PDF文档在视图上美观且易于分享,但其封闭的格式往往给数据分析带来了诸多困难。如果你在处理PDF报表数据时遇到了难题,不用担心,本文将为你提供一整套解决方案,帮助你顺利处理和分析PDF中的表格数据。
一、为什么PDF表格数据难以分析?
在讨论解决方案之前,我们需先了解为什PDF数据分析如此棘手。这主要有以下几个原因:
1. 格式限制:PDF文件是设计用来展示信息而非存储数据。其内容往往是为了视觉效果而排版,导致数据结构不明确。当你尝试提取表格数据时,可能面临列错位、合并单元格等问题。
2. 缺乏可编辑性:PDF文档通常不允许直接编辑,而数据分析需要对信息进行修改和清洗。这使得分析过程变得复杂且繁琐。
3. 缺少标准化:不同的PDF生成工具可能会以不同的方式处理表格数据,导致格式不统一。这不仅影响数据提取的效率,还可能引入额外的错误。
4. 图像嵌入:有些PDF文件中的表格可能是以图像形式嵌入,传统的文本提取工具无法识别这种格式,从而无法获取所需的数据。
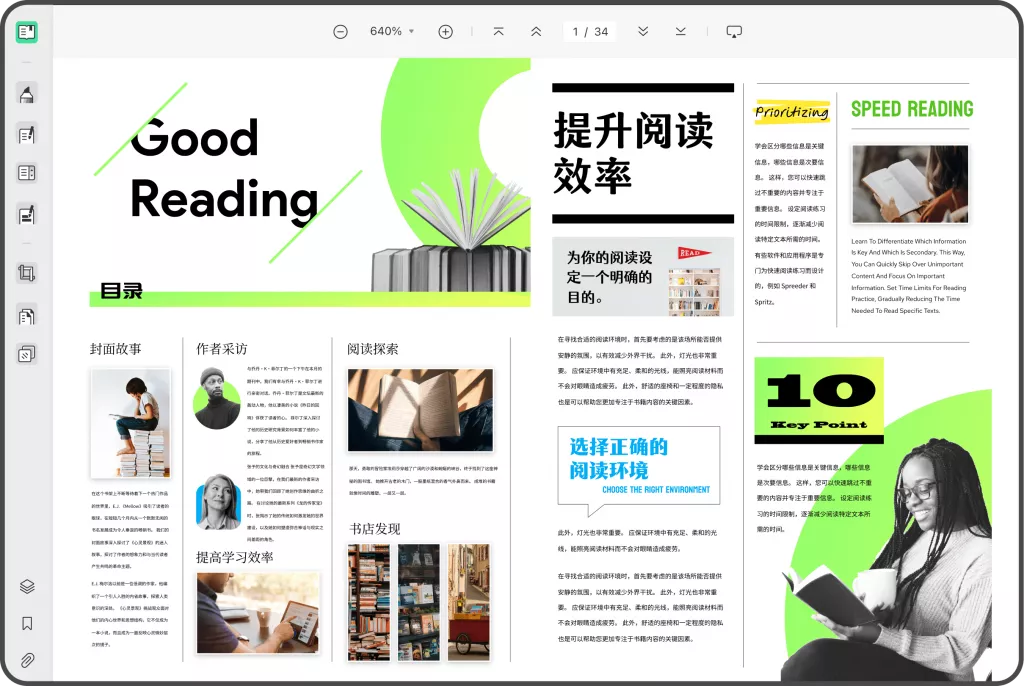
二、处理PDF报表数据的工具和方法
为了解决PDF表格数据无法分析的问题,以下是几种有效的方法和工具,可以帮助你轻松提取和处理PDF中的表格数据。
1. 使用PDF数据提取工具
随着技术的发展,市场上涌现出了许多专门用于提取PDF数据的工具。这些工具能够智能识别表格结构并将其转换为可编辑的格式。常用的工具包括:
– Adobe Acrobat Pro DC:作为PDF格式的发源者,Adobe的这个PDF编辑器提供了强大的数据提取功能,可以将PDF表格转换为Excel或Word文档。
– ABBYY FineReader:这是一款OCR光学字符识别软件,能够识别PDF中的文本和表格,并将其转换为可编辑的格式。
– UPDF:这是一款AI智能PDF编辑器,不仅可以编辑PDF文件的内容,还可以转换PDF文档的格式,将PDF转换为Excel表格文档格式。
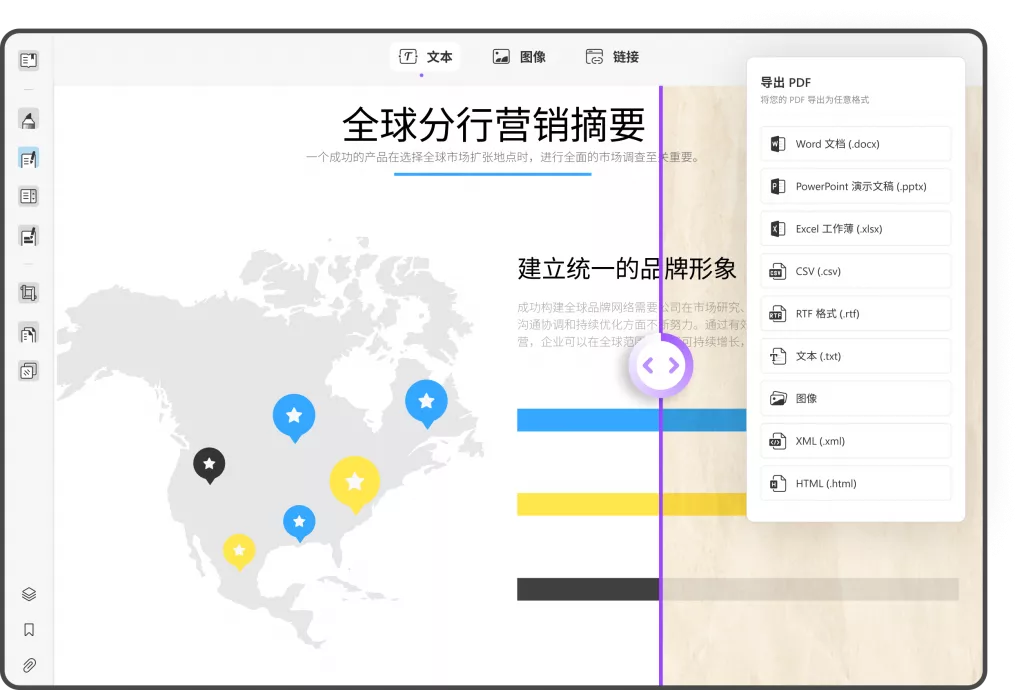
– Smallpdf:这是一个在线工具,支持将PDF文件转换为Excel、Word等格式,操作简单,适合快速使用。
2. 手动复制与粘贴
如果PDF文件的表格较小,且内容相对简单,你可以尝试手动复制并粘贴:
– 打开PDF文件,使用鼠标选中你需要的数据区域,复制(Ctrl+C)。
– 将其粘贴(Ctrl+V)到Excel或Word中。此时,可能需要进行格式调整,确保数据整齐。
然而,手动操作虽然简单,但对于大型或复杂数据来说,费时费力,并且容易出错。
3. 采用编程方式提取数据
对于需要处理大量PDF文件的用户,编程可能是最有效的方法。你可以使用Python等编程语言来提取PDF中的表格数据。
– 使用Python中的PyPDF2或pdfplumber库,这些库能够帮助提取PDF中的文本、表格甚至图像数据。
– pandas库结合tabula-py可以直接从PDF文件读取表格数据,生成DataFrame并进行分析处理。
通过编程方式将提升数据处理的效率,尤其适合需要定期分析PDF报表的企业。
三、数据分析的后续步骤
当成功提取PDF报表中的数据后,接下来的步骤是进行数据分析。以下是一些数据分析的基本步骤:
1. 数据清洗:在Excel或其他数据处理软件中,对提取的数据进行清洗,确保数据准确无误。删除重复项、修正错误,处理缺失值等。
2. 数据整理:将数据按照需要的格式整理,比如按时间、类别、数值等进行分类。这将利于后续的分析和可视化。
3. 数据分析:可以使用Excel的图表功能进行可视化,也可以使用数据分析软件如SPSS、R、Python进行更深入的统计分析。
4. 报告生成:根据分析结果生成报告,展示数据趋势及结论。一个清晰、准确的报告有助于做出更好的决策。
四、总结
处理PDF表格数据虽然面临许多挑战,但通过合适的工具与方法,可以有效地解决这些问题。无论是使用专业的数据提取工具,手动复制,还是通过编程方式提取数据,关键在于找到最适合自己的处理方法。希望本文中的信息能够帮助你顺利处理PDF报表数据,提升工作效率。
