Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 在线版
AI 在线版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志






 周年庆特惠,立减+加赠会员时长
周年庆特惠,立减+加赠会员时长



UPDF 的 OCR 功能允许您将 PDF 文档的扫描文本转换为可搜索和可编辑的内容。 使用此功能,还可以编辑跨图像的数据,使文档对用户具有交互性。
(官网Apple Chip版Mac有OCR功能,Intel Chip版Mac和Mac App Store版暂未推出OCR功能。)
如何下载和安装 OCR
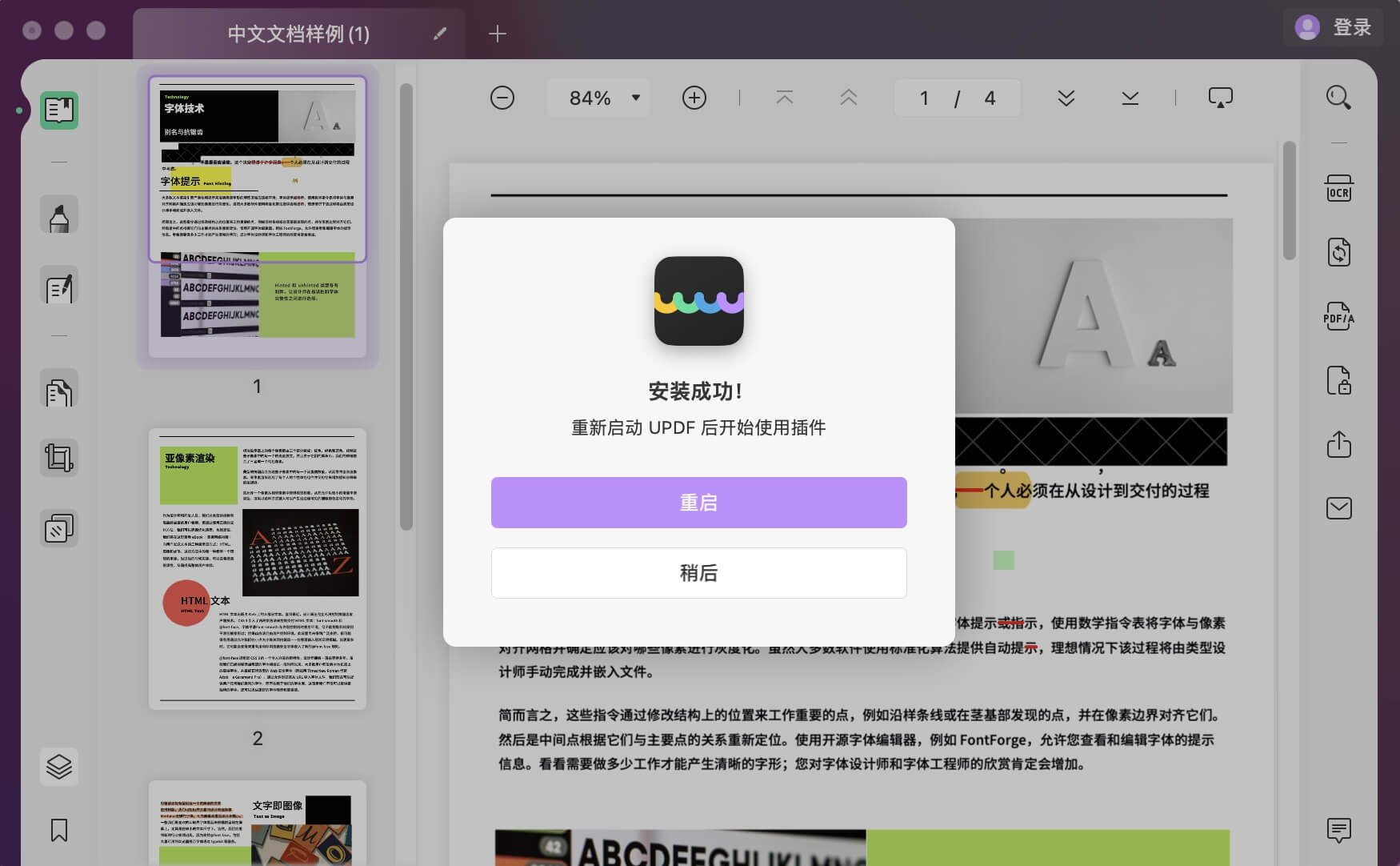
打开文档时,导航到右侧工具栏上的“使用 OCR 识别文本”按钮。
如果您是第一次使用此功能,则必须将其下载为 UPDF 插件。 单击弹出窗口中的“重启”按钮重启应用后则可以使用 OCR 功能。
如何 OCR PDFs
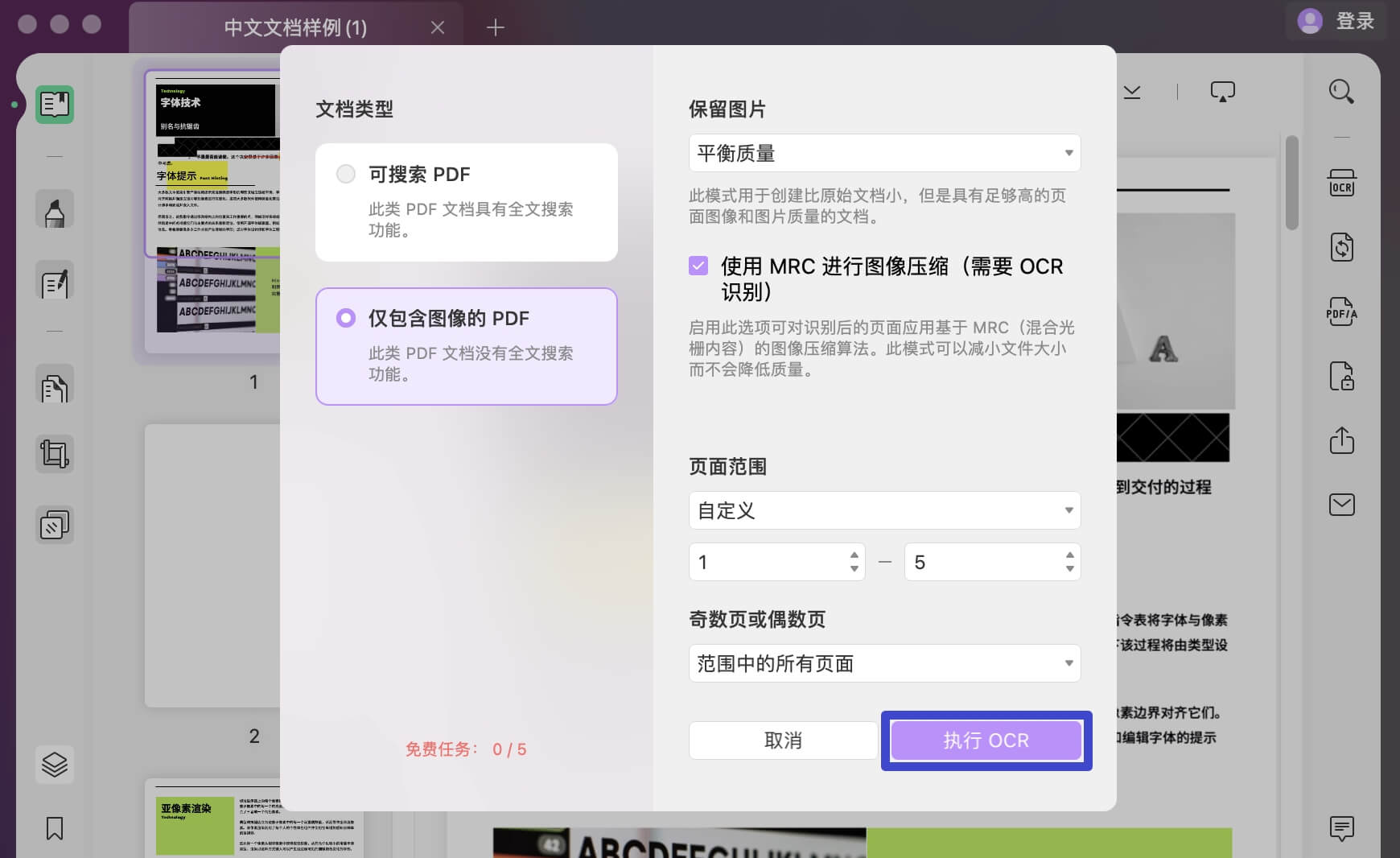
安装后,导航到相同的按钮以通过 UPDF 访问 OCR 工具。 当它打开时,它会为您提供两种不同的文档类型选项,包括“可搜索 PDF”和“仅包含图像的 PDF”。
- 可搜索 PDF:通过选择此选项,它将扫描的 PDF 文档转换为可搜索和可编辑的文档。
- 仅包含图像的 PDF:选择此选项后,它会将您的可搜索和可编辑文档转换为基于图像的 PDF 文档,该文档既不可搜索也不可编辑。
文档类型:可搜索的 PDF
如果您选择“可搜索 PDF”,它会将您扫描的 PDF 文档转换为可编辑和可搜索的文档。
布局
要进行此设置,您必须首先使用下拉菜单中的可用选项确定正确的“布局”。 设置布局时,您将获得三个不同的选项:
- 仅文本和图片:识别的文本和图像将保存在将要创建的 PDF 文档中。 创建的文件也更小,并且可能具有与原始文件不同的视觉结构。
- 页面图像上的文本:此模式负责在执行 OCR 的源文档中保留背景图像和插图。 这些文件更大; 但是,它们在视觉上可能与原件更相像。
- 页面图像下的文本:在此模式下,PDF图像被保留; 但是,已识别的文本位于图像下方的不可见层下。 此文件类型与原始 PDF 文件完全相同。
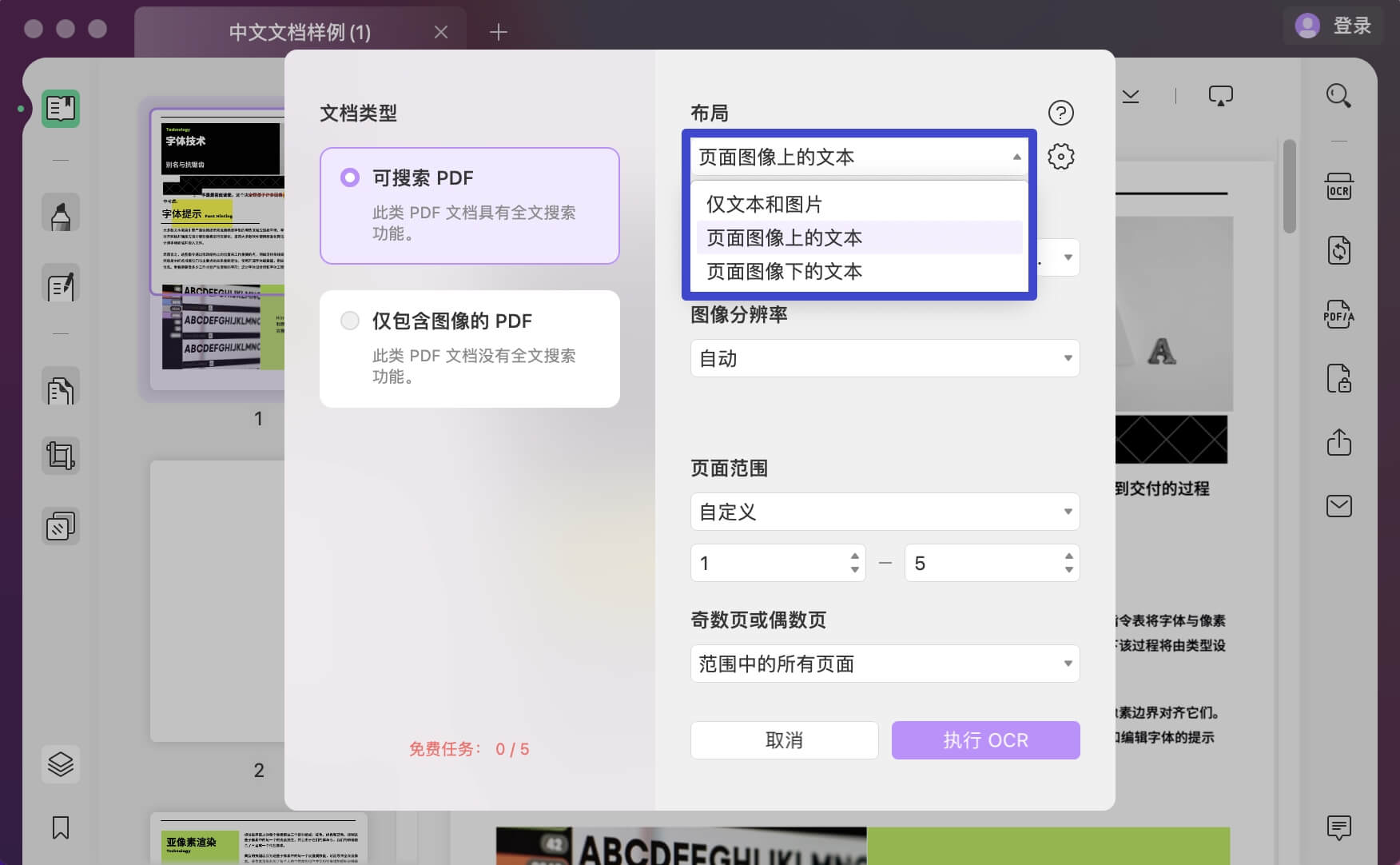
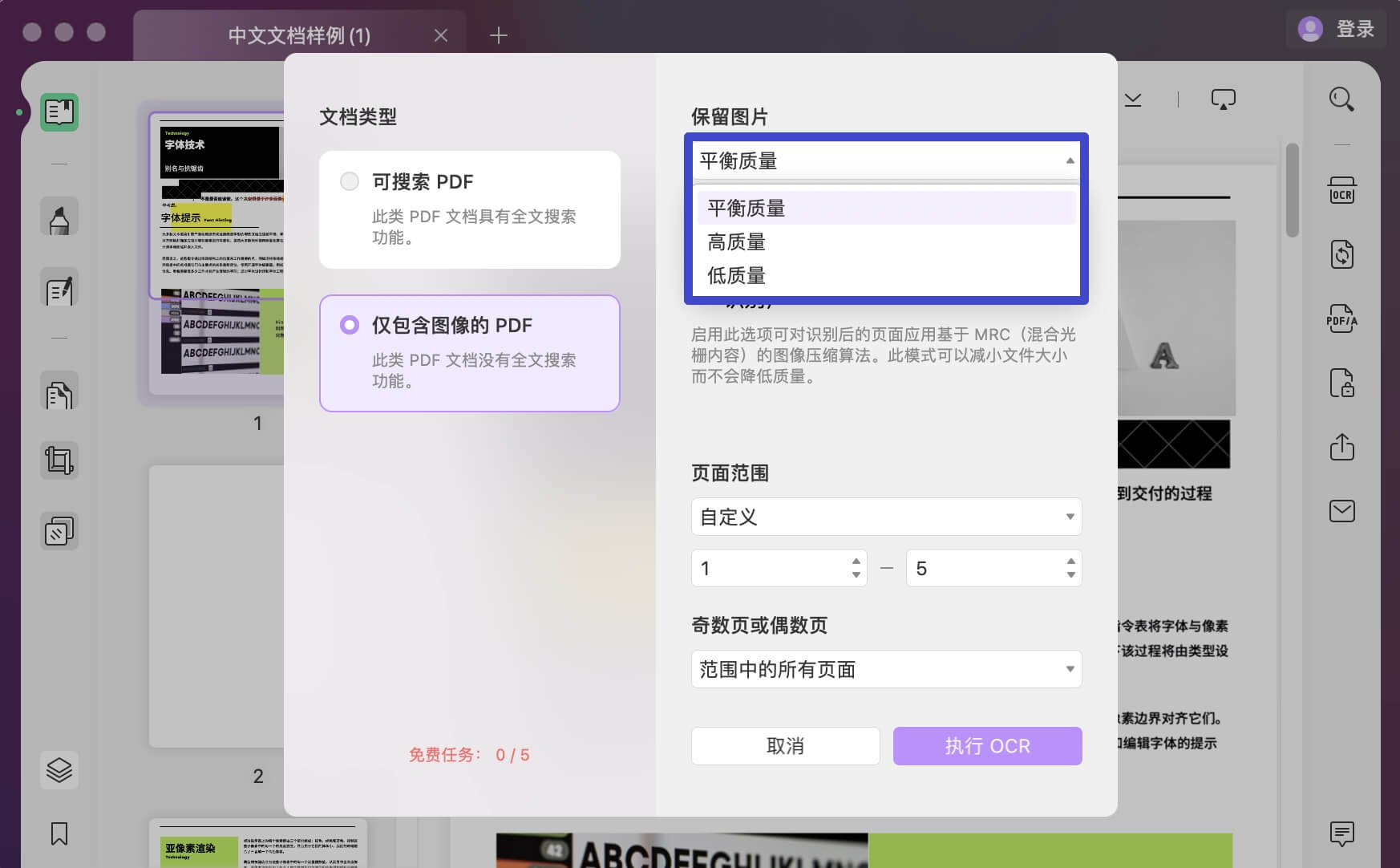
单击“齿轮”图标以访问您可以为文件定义的更多布局设置。 您可以在此处指定是否要“保留图片”,同时在“低质量”、“平衡质量”或“高质量”之间做出选择,以保存比原始文件更小的文件,但图像和图片质量值得称道。
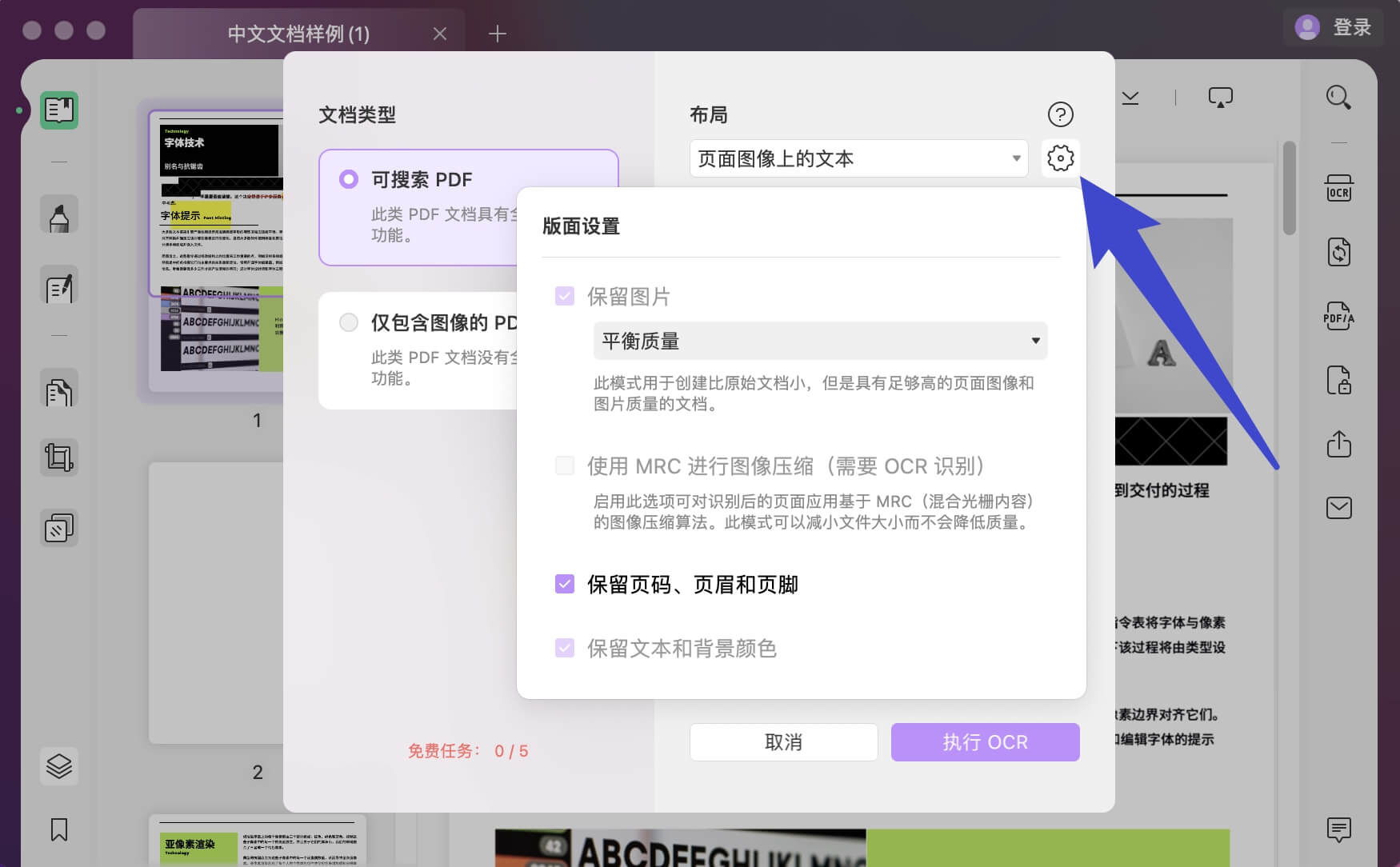
文档语言、图像分辨率和页面范围:
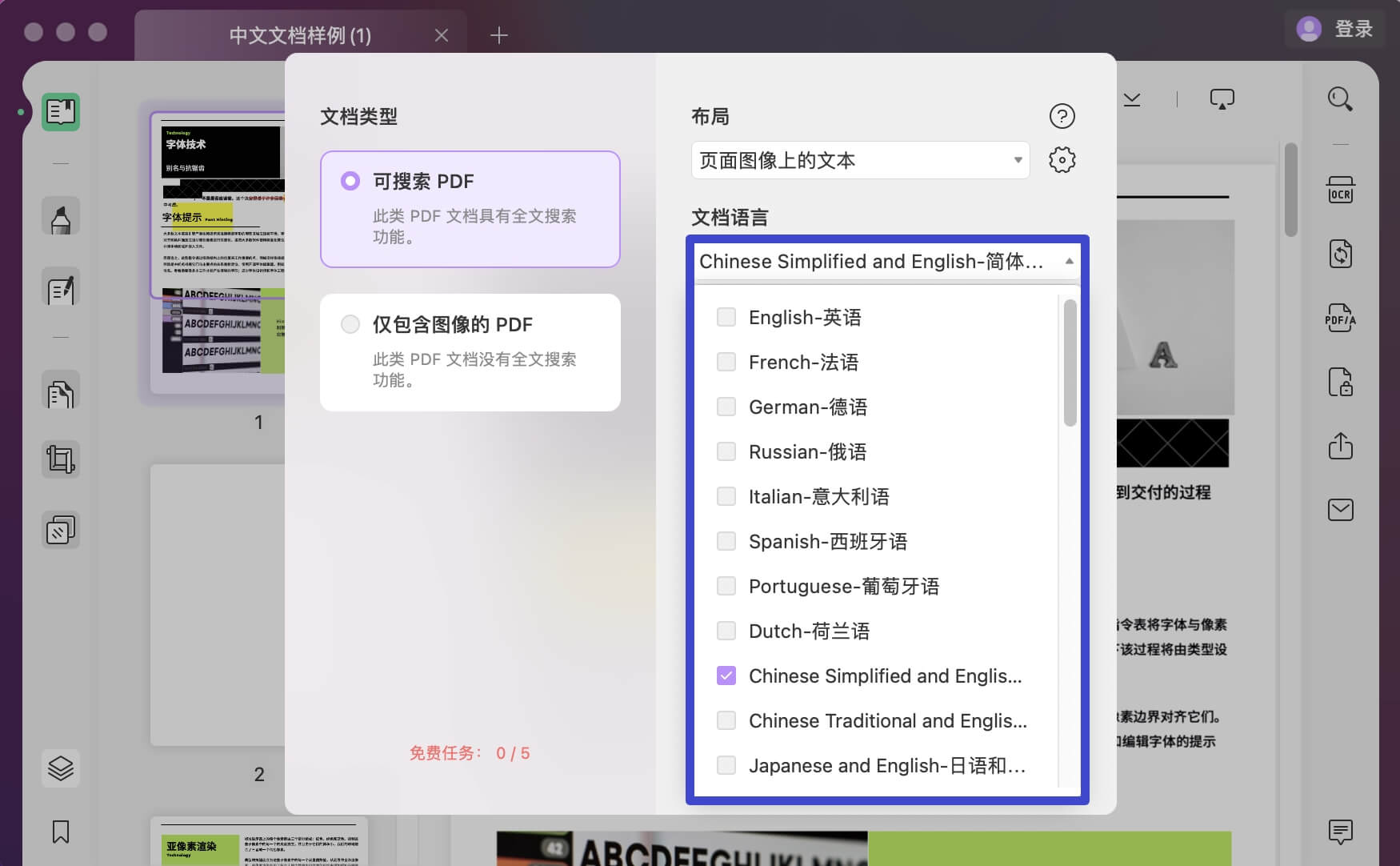
使用下拉菜单中的 38 种不同语言选项定义适当的文档语言。 这为 UPDF 提供了一个更好的基础来准确识别文档中的文本。
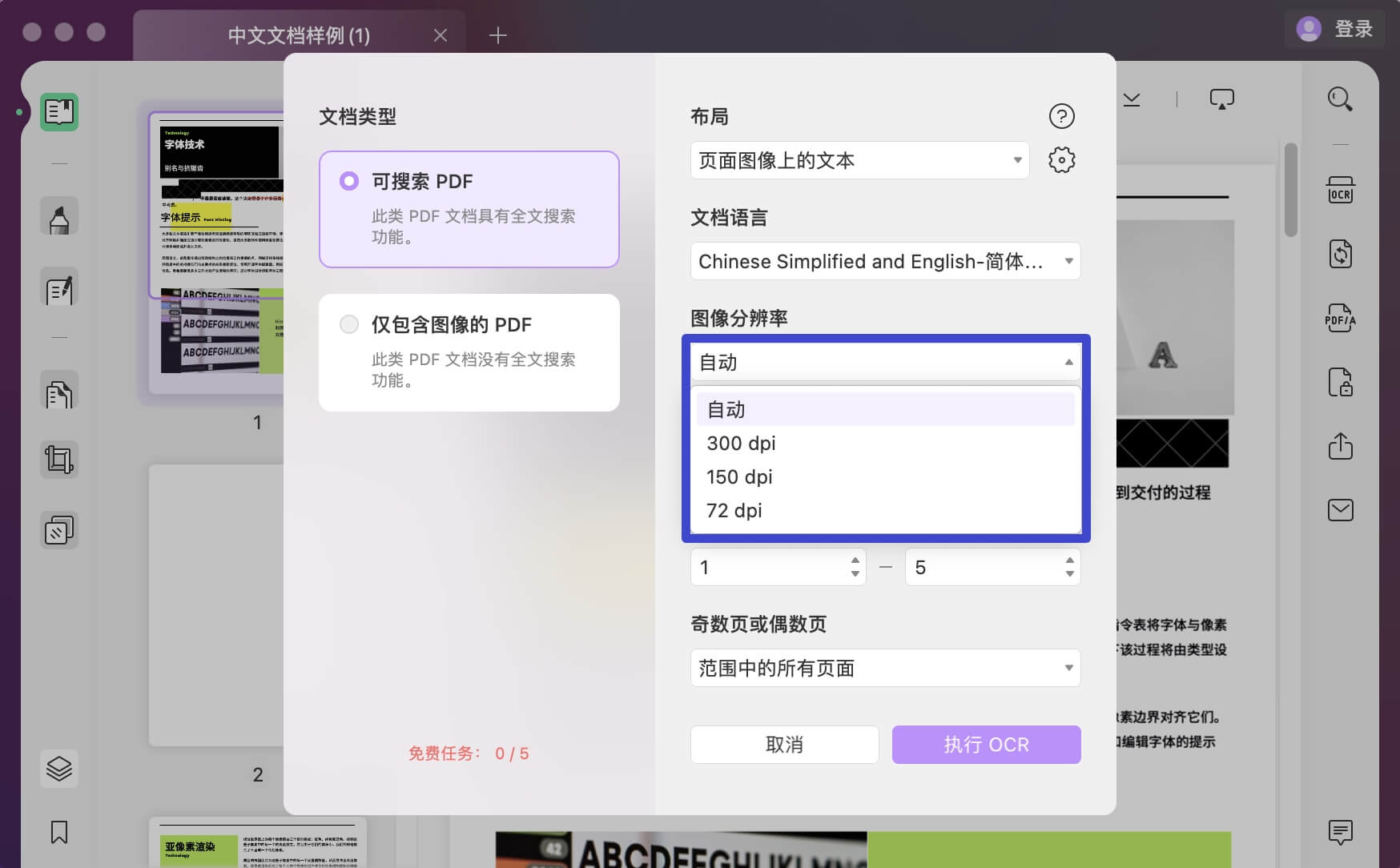
您还可以使用“图像分辨率”选项为图像指定适当的分辨率设置。 处理“页面范围”并单击“执行 OCR”以使用定义的设置在文件中执行 OCR。
文档类型:仅包含图像的 PDF
如果您继续使用“仅包含图像的 PDF”,它会将您可搜索和可编辑的文档转换为基于图像的 PDF 文档,这些文档既不可搜索也不可编辑。
- 通过选择“低质量”、“平衡质量”或“高质量”的任何可用选项,在“保留图片”部分下设置图像质量。
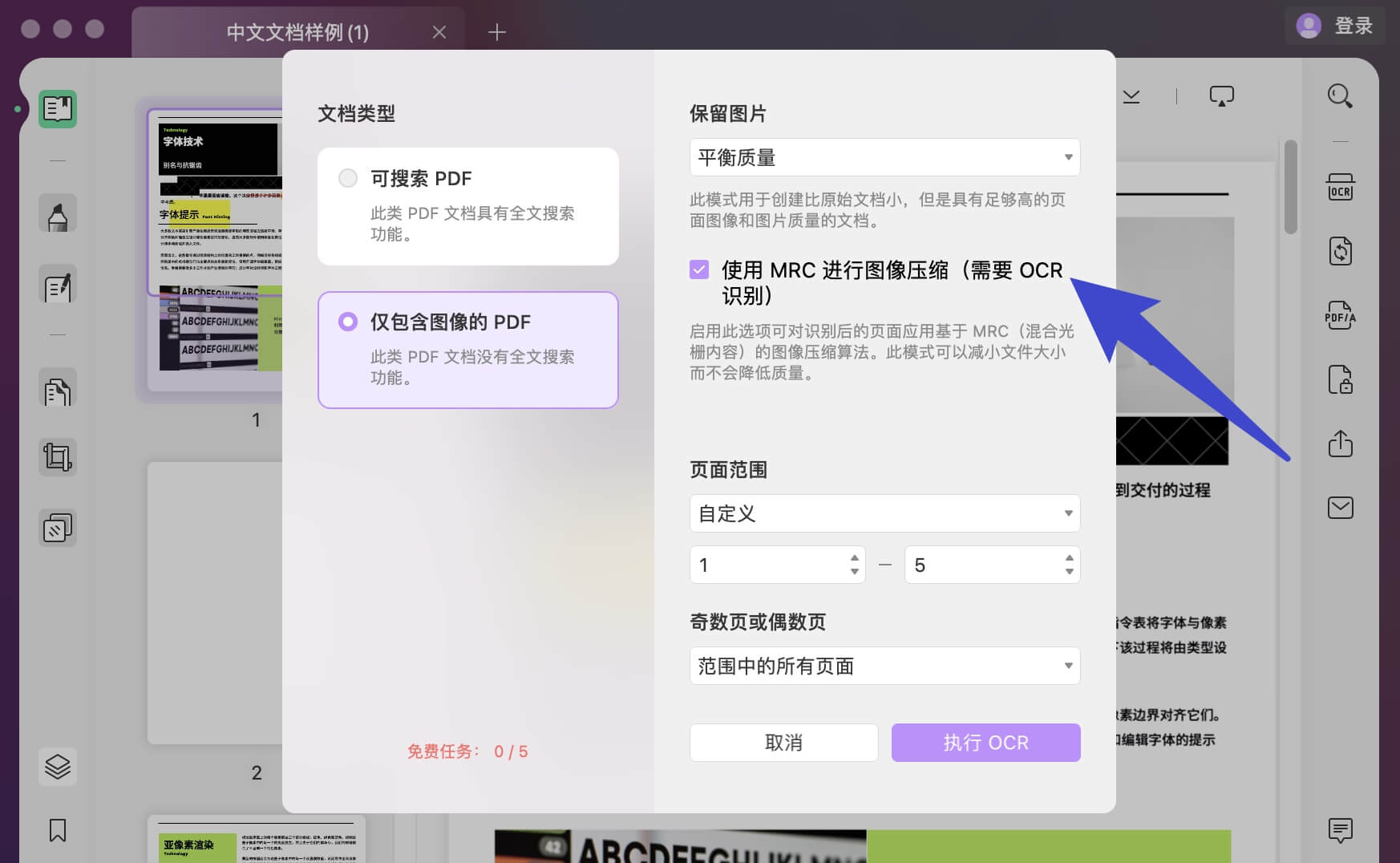
- 决定是否要使用 MRC 进行图像压缩。
- 提供适当的“页面范围”并单击“执行 OCR”以对文档执行操作。 选择文件夹,您将立即获得扫描的 PDF 文档。