 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志








想从PDF文件中导出表格数据,快速提取信息其实并不难!通过借助专业工具如UPDF,您可以将PDF中的表格精准提取为Excel格式,仅需几步即可完成。本文将详细介绍如何轻松高效地完成PDF表格的导出,避免手动复制带来的时间浪费与格式混乱问题。
1.为什么PDF文件中的数据难以提取?
PDF文件以固定布局著称,其设计初衷是为了跨平台共享内容时保持视觉一致性。然而,这种特点也让表格数据提取变得复杂。以下是主要原因:
- 固定格式:PDF中的表格内容通常嵌套在不可编辑的框架中,限制了直接复制或编辑的可能性。
- 复杂的排版:某些PDF文件中,表格可能包含多级嵌套、跨页内容或不规则的单元格分布,这会导致复制时数据排列混乱。
- 图像化表格:有些PDF中的表格实际上是图像格式,而非真实的文本数据,使得提取过程需要依赖OCR(光学字符识别)技术。
这些挑战意味着,想要精准提取PDF中的表格数据,单靠手动方法往往效率低下,使用专业工具成为最佳解决方案。
2.使用UPDF从PDF文件中导出表格的方法
要精准地从PDF文件中提取表格数据,UPDF为用户提供了高效解决方案。这款国产智能PDF编辑器支持跨平台操作,并提供简单易懂的操作流程,让即便是初次使用的用户也能快速上手。以下是详细步骤:
- 步骤一 在UPDF官网或应用商店下载适配的UPDF版本,支持Windows、Mac、iOS和Android系统。安装完成后,启动软件。
- 步骤二 点击主界面上的“打开文件”按钮,将需要导出表格的PDF文档导入UPDF。或者直接将文件拖拽到软件窗口,快速完成导入。
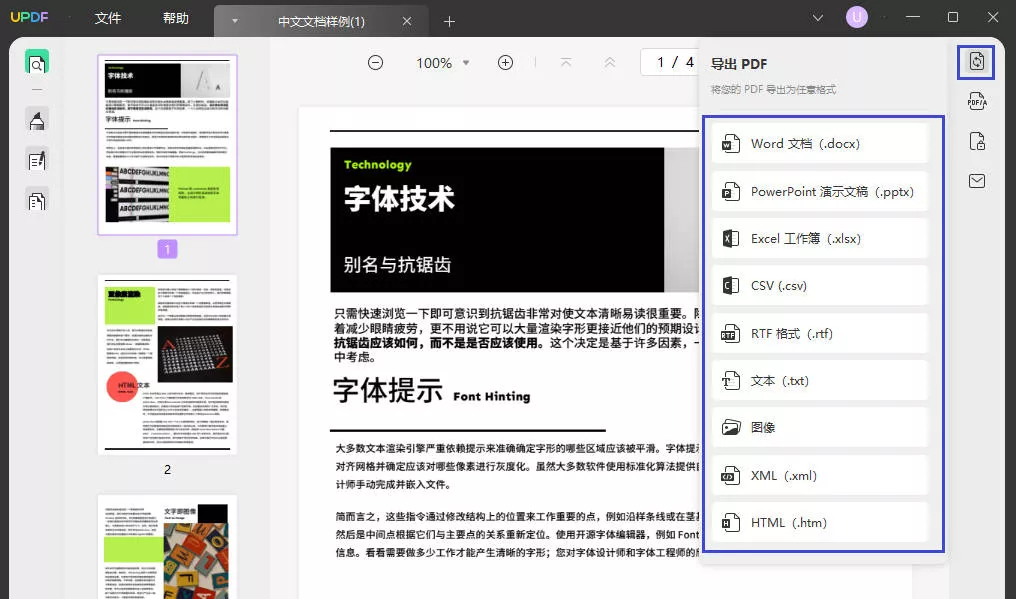
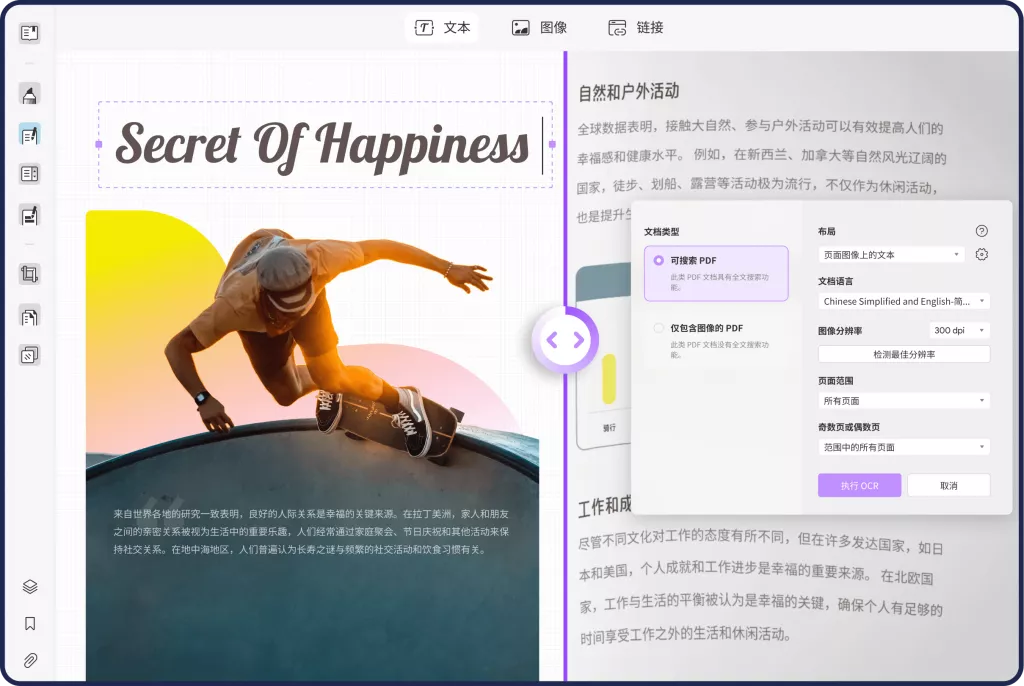
- 步骤三 在文件打开后,找到页面右侧的“导出PDF”功能按钮。点击后,会弹出导出选项菜单。
- 步骤四 在导出选项中,选择“Excel”作为目标文件格式。UPDF支持智能化识别PDF中的表格内容,并将其完整转换为Excel格式,确保数据精准提取。
- 步骤五 弹出的设置窗口允许用户自定义导出选项:
- 语言选择:如果PDF文件包含非中文或多语言表格,务必选择正确的语言,确保UPDF的OCR识别功能能够准确提取数据。
- 页面范围:选择需要导出的具体页面范围(如全文件或部分页面)。
- 步骤六 完成设置后,点击“导出”按钮。系统会提示选择保存路径,指定保存位置后,UPDF将自动完成PDF表格的提取并生成Excel文件。
- 步骤七 打开导出的Excel文件,检查表格数据是否完整。如有需要,可以调整导出设置后重新操作,或手动优化导出结果。
UPDF不仅具备精准识别的能力,还能保留表格的完整排版和格式,大大提升数据处理效率。
3.从PDF文件中提取数据的常见问题及解决方法
问题一:导出表格后格式错乱
有时,PDF表格导出到Excel后,可能会出现单元格位置混乱或数据排列异常的情况。这通常是由于原始PDF表格的排版较复杂或含有合并单元格。解决方法包括:
- 调整导出设置:使用UPDF导出时,可以手动指定需要提取的页面范围或表格区域,减少不必要的干扰内容。
- 手动优化:在导出后的Excel文件中调整单元格的布局和样式,快速修复格式问题。
问题二:部分数据未被正确识别
部分PDF文件中的表格可能使用图片嵌入或非标准文本编码,导致提取时部分数据未被识别。建议的解决方法如下:
- 启用OCR(光学字符识别)功能:UPDF的OCR功能可以将图片形式的表格转换为可编辑的文本表格,确保数据无遗漏。
- 检查文本层次:确保PDF文件包含可识别的文本层,而非仅由扫描图片组成。
问题三:表格内容与背景混合导致提取困难
某些PDF表格可能使用复杂背景或非标准样式,使得提取表格数据更加困难。应对方法包括:
- 隐藏背景内容:使用UPDF的“编辑”功能,可以删除背景元素,以突出表格内容。
- 手动标注表格区域:通过手动框选表格部分,确保导出时数据精准。
问题四:语言或特殊符号识别错误
如果表格中包含特殊字符或多语言内容(如中文、日文等),可能出现识别错误。解决方案如下:
- 选择支持多语言的OCR功能:UPDF的OCR支持多语言识别,能准确提取不同语言的表格内容。
- 校对数据:导出后检查特殊字符部分,并及时修改。
问题五:导出过程中系统卡顿或文件过大
对于超大PDF文件,导出表格时可能会导致系统运行缓慢或卡顿现象。可尝试以下方法:
- 压缩文件大小:使用UPDF的压缩功能,将PDF文件优化为更小体积,同时保留高质量内容。
- 分步处理:将大型PDF文件按页面分割为多个小文件后分别提取表格,再合并结果。
总结
从PDF文件中导出表格看似复杂,但借助UPDF等专业工具,操作可以变得十分简单。UPDF不仅能快速提取数据,还能确保表格的完整性和精准度,是处理PDF表格的理想选择。如果你还在为PDF表格提取问题烦恼,不妨尝试UPDF,轻松提升工作效率!
