 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志







需要大量用到PDF文档里的文字,但是上面是图片,没办法复制怎么办。难道只能认命的一个个打上去吗,那也太浪费时间了。那么,PDF怎么用OCR来识别文字呢?
有人或许会说可以一页页截图,然后识别文字。确实是个办法,但是还是比较麻烦。今天我就教大家一个更简单更智能的办法。那就是用OCR识别PDF文档中的文字。
找到一个带有OCR识别功能的PDF编辑器,这样PDF文档中难提取文字的难题就迎刃而解啦!我一般遇到这种问题就会用UPDF来解决。
OCR识别文字工具:UPDF
这个UPDF不仅可以用OCR识别文字,还能编辑PDF文档中的内容,页面简单易懂,操作起来非常便捷,里面还有强大的AI功能。经常需要编辑PDF文档的朋友就可以和我一样,备一个这样的软件,会方便很多,点击下方下载即可免费试用哦。

使用UPDF用OCR识别PDF文档的步骤如下:
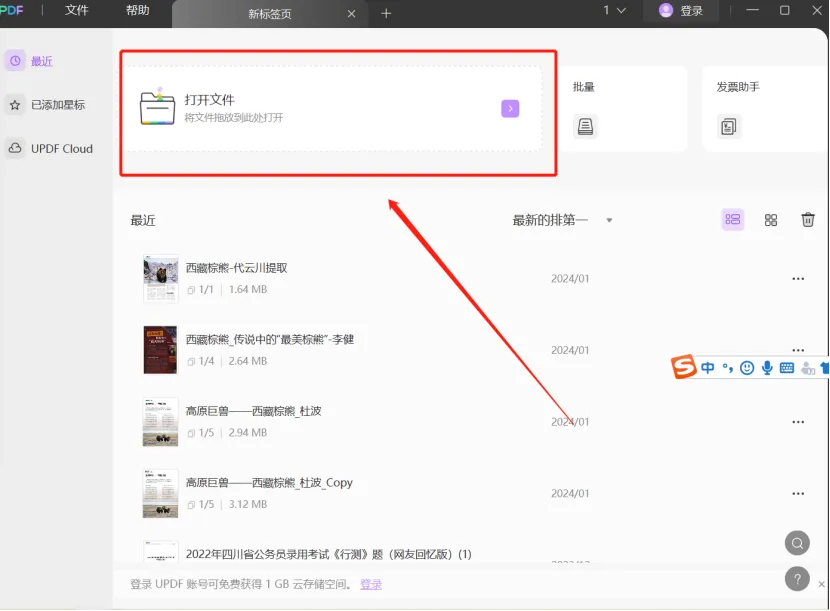
第一步,打开UPDF软件,在首页导入需要识别的PDF文档,将文件拖入下图红色框内后,会直接进入到编辑页面。
第二步,进入到阅读器模式后,可以看到页面两边有各种功能,非常的简单方便。现在我们找到OCR识别功能,鼠标单击即可。
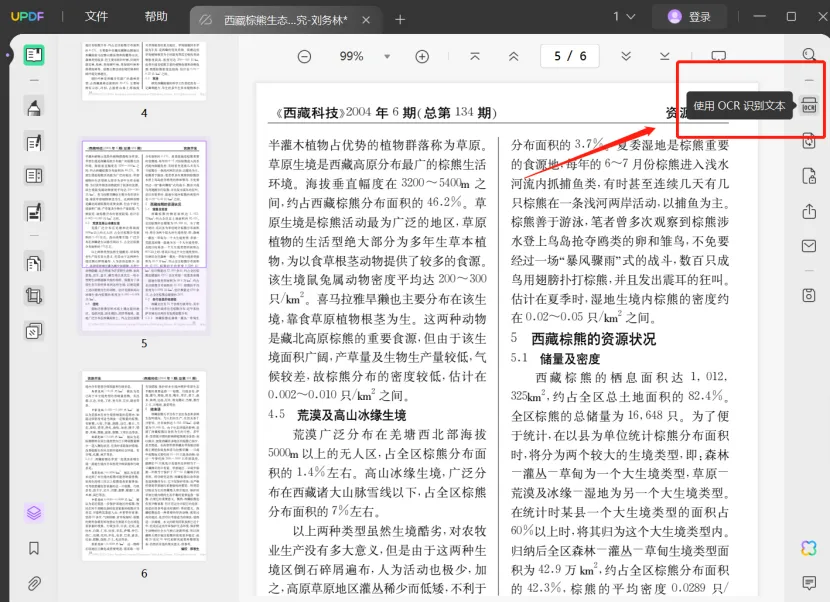
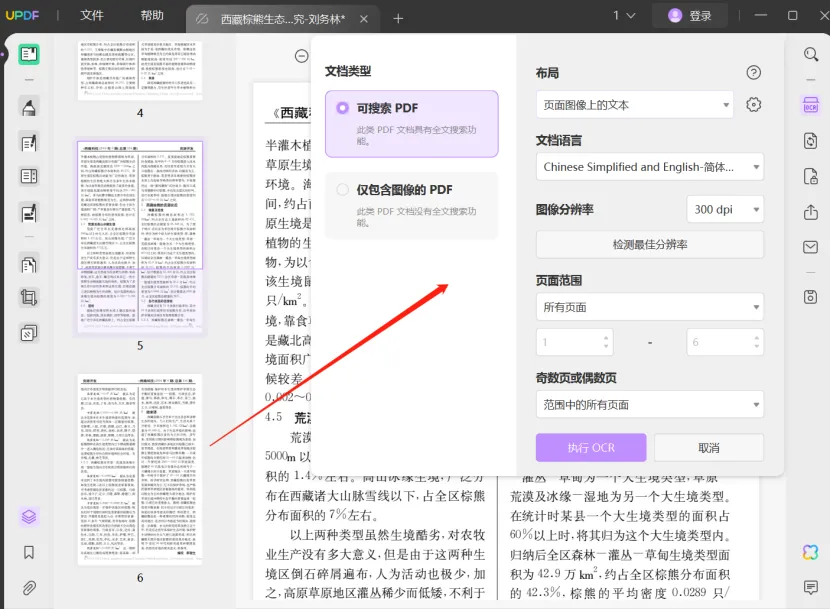
第三步,点击之后会弹出OCR识别的功能框,可以在布局里面选择你想要进行识别的内容,对相应功能做出调整后,点击下面执行OCR就完成了。
总结
用OCR识别文字是不是很方便,这样提取文字简单快捷,大家都快来学这个办法,事半功倍,提高效率,需要的朋友直接在商店搜UPDF,下载后还可以免费试用哦!

