 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志







想要从PDF文件中提取重要文本信息,可以借助UPDF这类专业的PDF编辑软件来实现。对于普通PDF文本,只需启用“PDF编辑”功能,并对目标内容进行复制即可完成提取;而对于包含图片或扫描内容的PDF文件,则需要使用OCR技术来进行提取。接下来,小编将详细介绍两种方法的具体操作步骤,助您轻松应对不同场景的需求。
从PDF文本中直接提取信息的方法
PDF文本提取是指直接从PDF文件中复制已有的文字内容。大多数PDF文件都包含可选中的文本,只需简单操作即可将重要信息提取并保存。以下是操作步骤详解:
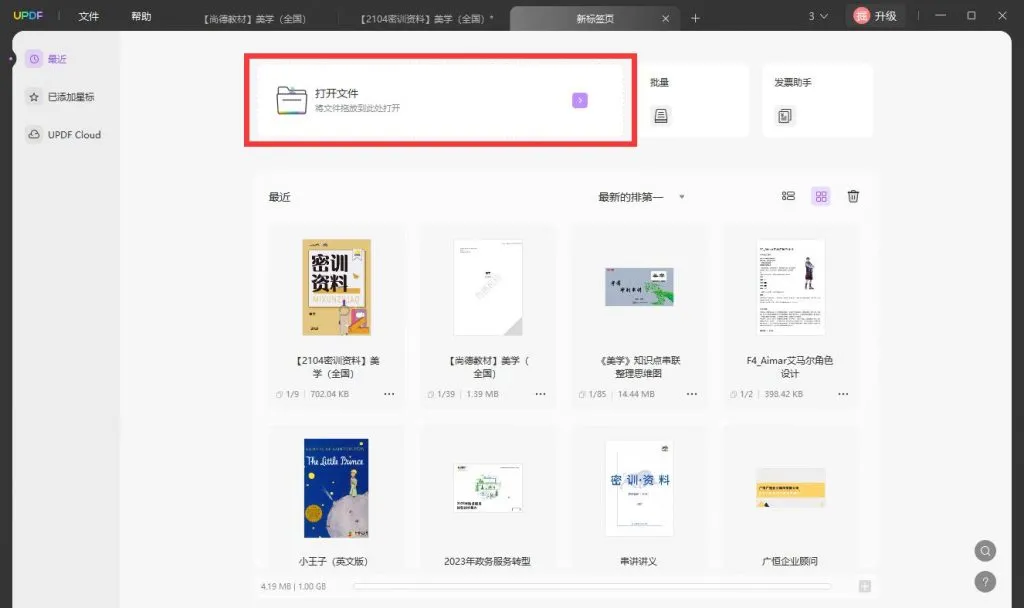
步骤一:加载PDF文件
- 打开UPDF软件,点击“打开文件”按钮,或者直接将PDF文档拖拽至UPDF的主界面。
- 并确保文件加载完成后进入主界面。
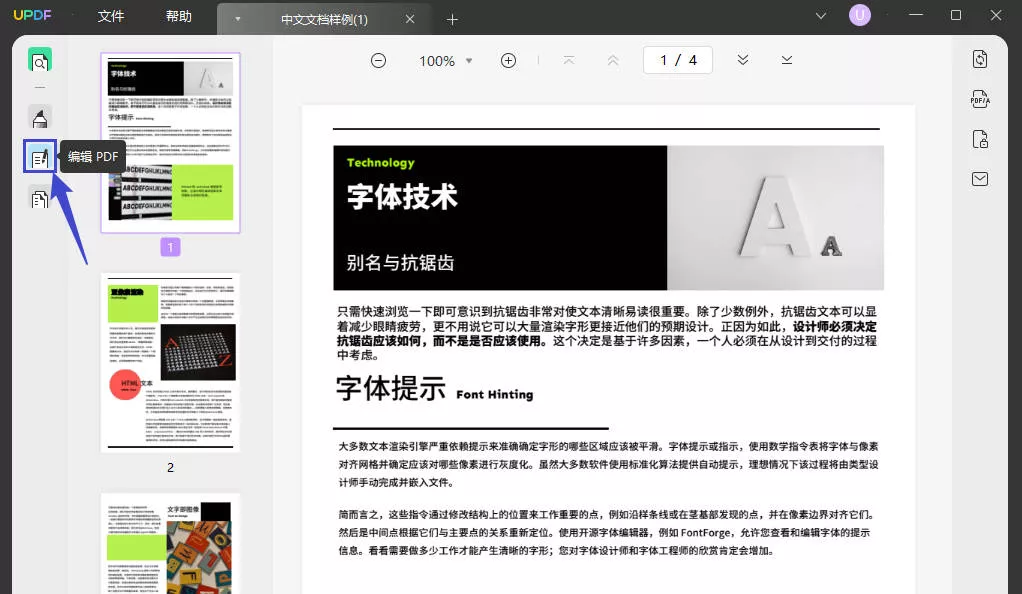
步骤二:进入编辑模式
- 在UPDF界面左侧,找到并点击“编辑PDF”图标。
- 文档将切换至可编辑状态,方便您选中所需的文本内容。
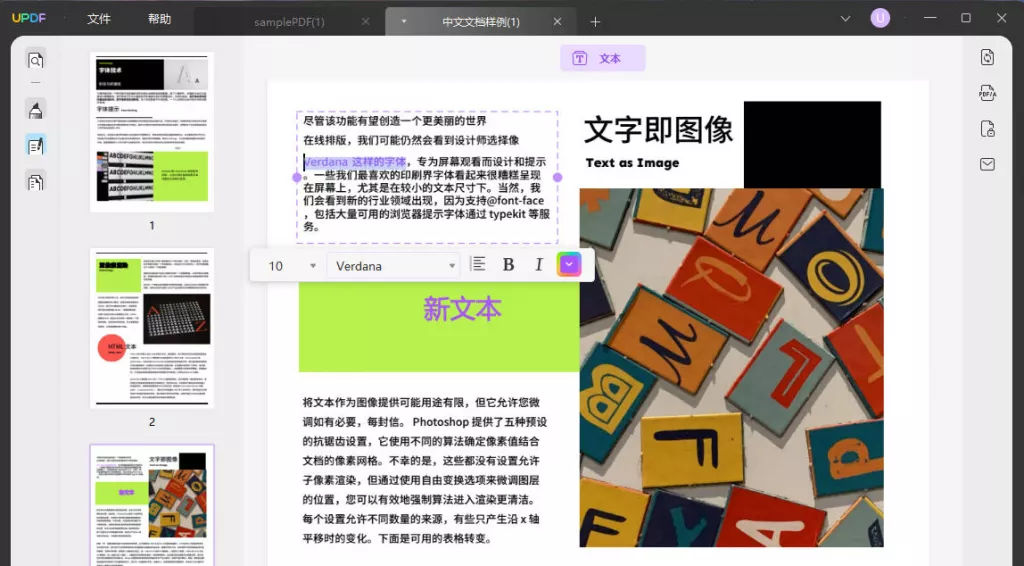
步骤三:选中并复制文本
- 使用鼠标点击并拖动选中目标文本。
- 右键点击选中的文本,选择“复制”选项。
- 打开目标文档(如Word、Notepad等),粘贴即可完成提取。
【小贴士】
- 确保文档未受密码保护或限制编辑功能,否则可能无法直接提取文本。
- 如果PDF文件文本无法选中,可能是扫描版或图片PDF,需使用OCR技术处理。
从PDF图片中提取文本信息的高效方法
UPDF提供专业的OCR功能,可识别多种语言和复杂布局,快速从图片中提取文字。无论是合同扫描件、图片广告,还是课程讲义,它都能轻松处理。以下是使用OCR提取图片文字的具体操作方法:
步骤一:上传PDF文件
打开UPDF,点击“打开文件”按钮,将需要处理的PDF文件加载到软件中。
步骤二:启动OCR功能
文件加载完成后,点击右侧的“使用OCR识别文本”图标,进入OCR设置界面。
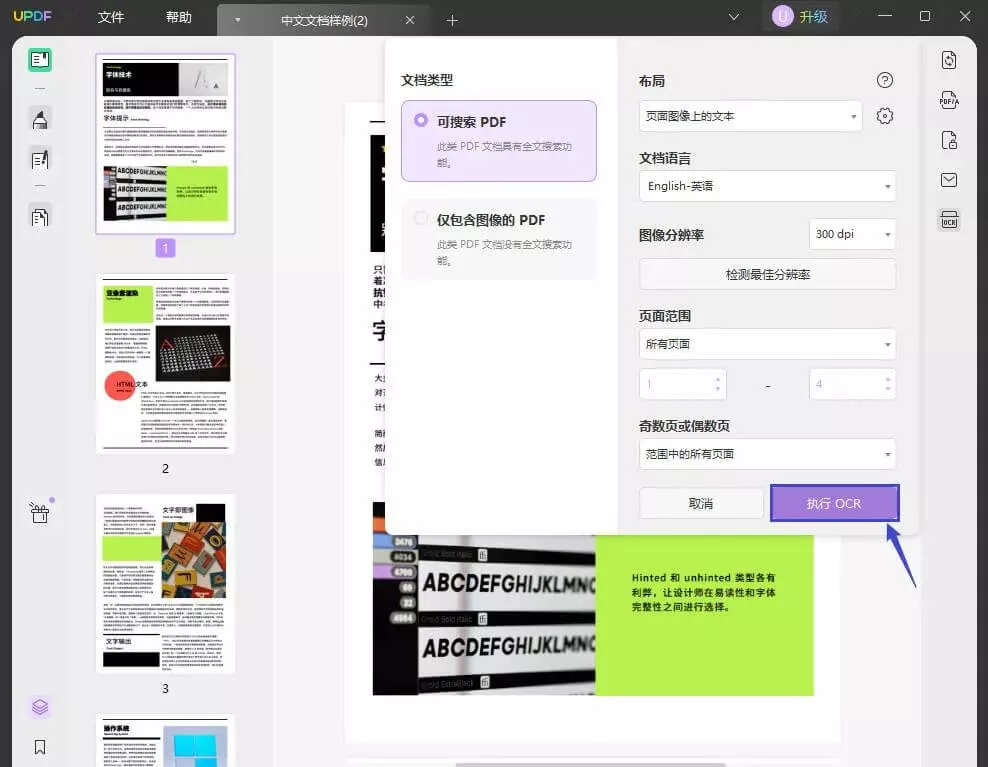
步骤三:配置OCR选项
- OCR模式:选择“可搜索PDF”模式,以便后续查找和编辑。
- 语言选择:设置PDF内容的语言,如中文、英文等,提高识别准确性。
- 布局与分辨率:选择保留原有布局或简化格式,并根据文件质量调整分辨率。
- 页面范围:可选择处理整个文档或指定页面,灵活应对不同需求。
步骤四:执行OCR识别
- 点击“执行OCR”按钮,UPDF会快速处理文档并生成可编辑文本。
- 识别完成后,您可以选中目标内容,右键复制,轻松提取文字。
OCR常见问题及解决方法
- 识别不准确:确保正确设置语言选项并使用高清扫描件。
- 处理速度慢:减少OCR的页面范围或优化图片分辨率设置。
如何根据需求选择提取方式
在使用UPDF提取文本信息时,不同类型的PDF文件适用不同的方法:
- 普通PDF文本:可直接进入编辑模式复制,操作简单快速。
- 图片PDF或扫描件:需借助OCR技术,将图片转化为可编辑文本。
根据文件属性选择适当的提取方式,能大幅提高效率。如果您经常处理复杂PDF文件,建议充分利用UPDF的OCR功能,灵活处理各种场景。
总结
无论是从PDF文件中直接提取文本内容,还是从图片中识别文字,UPDF都为用户提供了便捷、高效的解决方案。通过编辑模式,不仅可以修改和增减PDF文件中的文字内容,还可以完成一键复制并提取重要信息;而借助OCR技术,则可轻松处理扫描版或图片PDF文件。如果您还在为提取PDF信息而烦恼,赶快试试UPDF吧!
