 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版 AI 网页版
AI 网页版 AI 助手
AI 助手 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF  UPDF Cloud
UPDF Cloud 格式转换
格式转换 OCR 识别
OCR 识别 压缩 PDF
压缩 PDF 页面管理
页面管理 表单与签名
表单与签名 发票助手
发票助手 文档安全
文档安全 批量处理
批量处理 企业解决方案
企业解决方案 企业版价格
企业版价格 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 常见问题
常见问题 联系我们
联系我们 用户指南
用户指南 产品动态
产品动态 新闻中心
新闻中心 技术参数
技术参数 关于我们
关于我们 更新日志
更新日志







在现代办公中,PDF文件的使用已成为一种普遍现象。无论是学术论文、商务报告,还是个人文档,PDF凭借其良好的排版效果和跨平台特性而被广泛应用。然而,用户在处理PDF文件时,常常会遇到如何导出特定页面或将PDF页面提取为图片的问题。本文将深入探讨这些问题,提供全面详尽的解决方案,帮助你更高效地处理PDF文档。
一、PDF文件的结构
在探讨处理PDF页面的具体方法之前,首先需要了解PDF文件的基本结构。PDF是由Adobe公司开发的一种文件格式,旨在无论在何种设备上都能保持文档的原有排版和格式。PDF文件由若干页面组成,每一页都是一个独立的图层,可以包含文本、图形和图像。
PDF文件的结构使得在提取页面或将其转换为图片时需要特别注意。不同的PDF文件可能会存在不同的编码方式、嵌入的字体及图形对象等,这些都可能影响后续的处理过程。
二、导出PDF页面的几种方法
1. 使用专业软件
在市面上,许多专业的PDF编辑软件提供了页面导出的功能,比如UPDF、Adobe Acrobat、Foxit PDF Editor等。以下是一个详细的步骤指导,使用UPDF作为例子:
– 打开PDF文件:启动UPDF软件,点击“文件”,选择“打开”,找到并打开你需要处理的PDF文件。
– 选择导出工具:在顶部菜单中,选择“文件”>“导出到”>“图像”,然后可以选择导出为PNG、JPEG等格式。
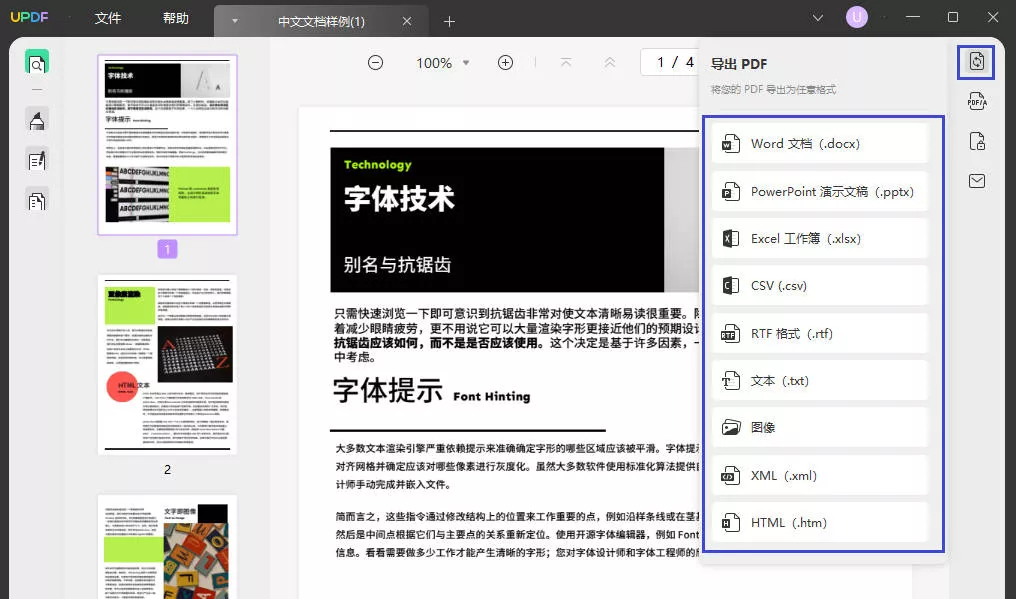
– 设置页面范围:在导出窗口中,通常会有一个选项可以选择导出所有页面或指定的页面范围。根据需要勾选相应的选项。
– 确认导出设置:在确认导出之前,可以设置图像的分辨率、质量等选项,以确保导出的图片符合需求。
– 保存文件:选择文件保存的位置及命名,然后点击“保存”即可完成页面的导出。
2. 使用在线工具
如果不想下载和安装软件,使用在线工具也是一个不错的选择。诸如Smallpdf、ILovePDF等网站提供了免费在线处理PDF的服务。具体步骤如下:
– 访问在线工具:打开Smallpdf或ILovePDF网站,选择与PDF处理相关的功能。
– 上传PDF文件:点击上传按钮,选择你的PDF文件,等待文件上传完成。
– 选择导出格式:选择你需要导出的格式,通常会有JPEG、PNG等多种选择。根据需要选择相应的格式。
– 下载文件:处理完成后,系统会提供一个下载链接,点击下载即可将转换后的文件保存到本地。
3. 通过编程实现自动化导出
对于一些需要大批量处理PDF文件的用户,可能会希望使用编程工具进行自动化处理。比如,使用Python语言和PyPDF2库可以高效地提取PDF页面:
```python
import PyPDF2
pdf_file_path = 'example.pdf'
page_number = 1 从第二页开始提取
output_pdf_path = 'output.pdf'
with open(pdf_file_path, 'rb') as file:
reader = PyPDF2.PdfFileReader(file)
writer = PyPDF2.PdfFileWriter()
添加指定页面
writer.addPage(reader.getPage(page_number))
with open(output_pdf_path, 'wb') as output_file:
writer.write(output_file)
```上面的代码示例展示了如何使用Python库来提取出特定页面,并保存为新的PDF文件。
三、注意事项与建议
在处理PDF页面导出及提取为图片的过程中,用户需要注意以下几点:
– 版权问题:在处理和分享PDF文档时,请确保遵守版权规定,避免侵犯他人的知识产权。
– 备份原文件:在进行PDF文件的编辑和导出时,建议备份原始文件,以防出现操作失误导致的文件损坏。
– 选择合适的工具:根据个人需求选择合适的工具。如果只是偶尔需要处理,在线工具会更加方便;但是对于频繁和批量处理,专业软件或编程解决方案会更高效。
总结
无论是导出PDF页面还是将页面提取为图片,掌握正确的方法和工具能够极大提高工作效率。在现代办公中,灵活运用这些技术,能够更好地处理和分享文档信息。希望本文对你有所帮助,让你的PDF处理工作变得更加简单高效。
