 AI 网页版
AI 网页版 Windows 版
Windows 版 Mac 版
Mac 版 iOS 版
iOS 版 安卓版
安卓版

 AI 单文件总结
AI 单文件总结 AI 多文件总结
AI 多文件总结 生成思维导图
生成思维导图 深度研究
深度研究 论文搜索
论文搜索 AI 翻译
AI 翻译  AI 解释
AI 解释 AI 问答
AI 问答 编辑 PDF
编辑 PDF 注释 PDF
注释 PDF 阅读 PDF
阅读 PDF PDF 表单编辑
PDF 表单编辑 PDF 去水印
PDF 去水印 PDF 添加水印
PDF 添加水印 OCR 图文识别
OCR 图文识别 合并 PDF
合并 PDF 拆分 PDF
拆分 PDF 压缩 PDF
压缩 PDF 分割 PDF
分割 PDF 插入 PDF
插入 PDF 提取 PDF
提取 PDF 替换 PDF
替换 PDF PDF 加密
PDF 加密 PDF 密文
PDF 密文 PDF 签名
PDF 签名 PDF 文档对比
PDF 文档对比 PDF 打印
PDF 打印 批量处理
批量处理 发票助手
发票助手 PDF 共享
PDF 共享 云端同步
云端同步 PDF 转 Word
PDF 转 Word PDF 转 PPT
PDF 转 PPT PDF 转 Excel
PDF 转 Excel PDF 转 图片
PDF 转 图片 PDF 转 TXT
PDF 转 TXT PDF 转 XML
PDF 转 XML PDF 转 CSV
PDF 转 CSV PDF 转 RTF
PDF 转 RTF PDF 转 HTML
PDF 转 HTML PDF 转 PDF/A
PDF 转 PDF/A PDF 转 OFD
PDF 转 OFD CAJ 转 PDF
CAJ 转 PDF Word 转 PDF
Word 转 PDF PPT 转 PDF
PPT 转 PDF Excel 转 PDF
Excel 转 PDF 图片 转 PDF
图片 转 PDF Visio 转 PDF
Visio 转 PDF OFD 转 PDF
OFD 转 PDF 创建 PDF
创建 PDF PDF 转 Word
PDF 转 Word PDF 转 Excel
PDF 转 Excel PDF 转 PPT
PDF 转 PPT 企业解决方案
企业解决方案 企业版定价
企业版定价 企业版 AI
企业版 AI 企业指南
企业指南 渠道合作
渠道合作 信创版
信创版 金融
金融 制造
制造 医疗
医疗 教育
教育 保险
保险 法律
法律 政务
政务



 常见问题
常见问题 新闻中心
新闻中心 文章资讯
文章资讯 产品动态
产品动态 更新日志
更新日志 科研指南
科研指南













OCR是一种将图片或扫描文件中的文字转化为可编辑文本的技术,它在提高工作效率、文件管理和数字化过程中具有重要作用。借助OCR技术,用户可以从扫描的文档或图像中快速提取文字,减少手动输入的时间。本文将详细介绍OCR的定义、功能及其在实际应用中的优势,并探讨如何利用UPDF软件的OCR功能实现更高效的文件处理。
什么是OCR光学字符识别?
OCR(Optical Character Recognition),中文称为光学字符识别,是一种通过扫描设备或数字图像处理技术,将印刷或手写文本从图像中识别并转换为可编辑、可搜索的文本内容的技术。OCR的核心在于将图像上的非结构化数据,如书籍、发票、报表、身份证等文档中的文字提取出来,方便后续的编辑、整理与存储。
这种技术的工作流程通常包括三个步骤:
- 图像预处理:去除噪点、调整对比度,使图像更加清晰,以提高识别率。
- 字符识别:通过模式识别和机器学习算法,逐字逐句地将图像中的字符转化为可编辑的文本。
- 后期处理:对识别到的文本进行语法和拼写校对,以提高文本的准确度。
随着人工智能和深度学习的发展,OCR的识别精度和应用场景得到了显著提升,不仅能够识别印刷体文字,连手写体也可以准确识别。
OCR的作用和应用场景
OCR技术的作用十分广泛,它的出现大大提高了企业和个人的工作效率。以下是几个典型的应用场景:
- 文档数字化:许多企业需要将大量的纸质文件转换为电子档案,OCR技术可以帮助他们快速完成这项任务。通过扫描文件并使用OCR技术,用户可以将大量的文件转换为可编辑的数字文本,方便存储和查找。
- 票据与发票处理:金融机构和企业通常需要处理大量的发票和票据。传统手动录入费时费力,且易出错。OCR可以自动从扫描的票据中提取关键信息,如日期、金额和发票编号,极大地简化了工作流程。
- 学术研究:OCR技术广泛应用于学术领域。研究人员可以通过OCR将书籍或期刊中的文献扫描并转化为可搜索的文本,帮助他们快速定位所需内容,从而提高研究效率。
- 法律与医疗行业:在法律和医疗行业,海量的文件处理是日常工作的一部分。通过OCR技术,律师和医生可以将合同、病例等文档进行数字化处理,提高查阅和检索的速度。
OCR与UPDF:让文档处理更加高效
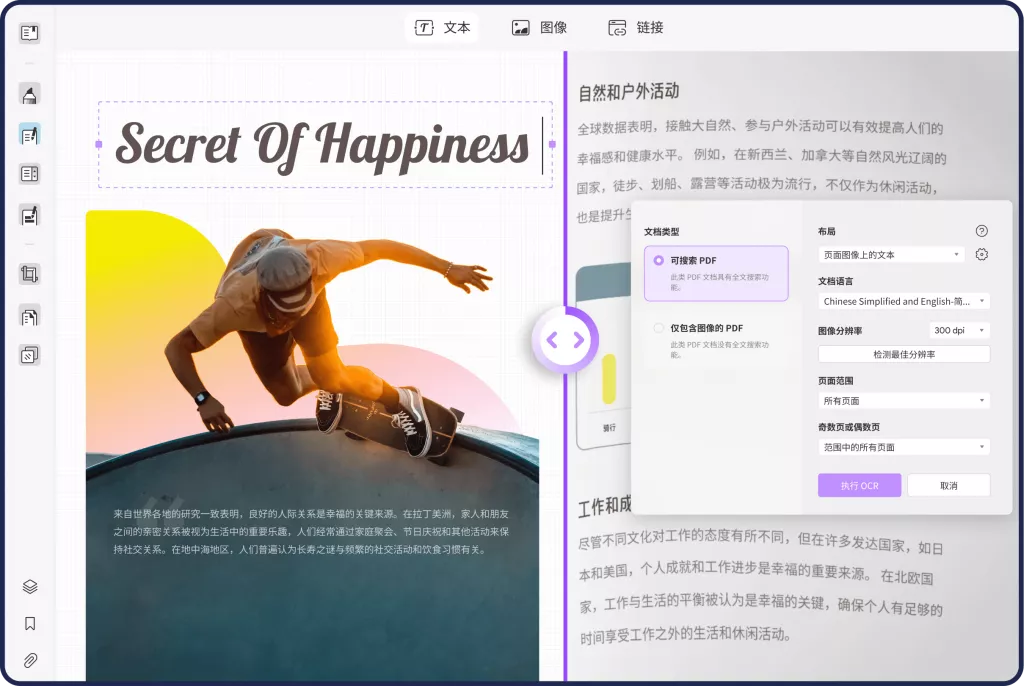
在市场上,许多PDF编辑工具都具备OCR功能,但UPDF的OCR功能凭借其简洁易用的界面、强大的识别能力和多语言支持,脱颖而出。UPDF不仅可以识别中文、英文、法语、德语等20多种语言,还能处理复杂的PDF文档,适应不同的文档需求。以下是UPDF OCR功能的详细步骤:
- 导入文件:打开UPDF软件,将需要识别的PDF文档拖拽到软件中,即可自动进入编辑页面。
- 启动OCR功能:在界面右侧找到“使用OCR识别文本”按钮,点击后会出现OCR功能的相关选项。
- 选择布局和语言:根据文档的类型,用户可以选择“可搜索PDF”或“仅包含图像的PDF”。同时,UPDF支持多种语言,用户可以根据需求选择适合的语言进行识别。
- 调整参数:用户可以调整OCR的识别精度、页面范围、图片分辨率等参数,以确保识别结果的准确性。
- 执行OCR:设置完成后,点击“执行OCR”,UPDF会自动将图像中的文字转换为可编辑文本,用户可以直接进行复制、修改和保存。
UPDF的OCR功能不仅适用于日常办公和学习,还可以满足复杂的企业级文档处理需求。无论是扫描文档的批量处理,还是多语言文档的识别,它都表现出色。
总结
OCR技术已经成为现代办公、学习和生活中不可或缺的工具。通过它,我们能够更快、更准确地处理文档,提升效率。而UPDF的OCR功能,凭借其用户友好的界面和强大的功能,成为了PDF处理工具中的佼佼者。如果你也有大量PDF文档需要处理,不妨试试UPDF,享受更加高效的办公体验。

